A Unified Approach to Submodular Maximization Under Noise
Dec 10, 2025

Generalized Principal-Agent Problem with a Learning Agent
Classic principal-agent problems such as Stackelberg games, contract design, and Bayesian persuasion, often assume that the agent is able to best respond to the principal’s committed strategy. We study repeated generalized principal-agent problems under the assumption that the principal does not have commitment power and the agent uses algorithms to learn to respond to the principal. We reduce this problem to a one-shot generalized principal-agent problem where the agent approximately best responds. Using this reduction, we show that: (1) If the agent uses contextual no-regret learning algorithms with regret $\mathrm{Reg}(T)$, then the principal can guarantee utility at least $U^* - \Theta\big(\sqrt{\tfrac{\mathrm{Reg}(T)}{T}}\big)$, where $U^*$ is the principal’s optimal utility in the classic model with a best-responding agent. (2) If the agent uses contextual no-swap-regret learning algorithms with swap-regret $\mathrm{SReg}(T)$, then the principal cannot obtain utility more than $U^* + O(\frac{\mathrm{SReg(T)}}{T})$. But (3) if the agent uses mean-based learning algorithms (which can be no-regret but not no-swap-regret), then the principal can sometimes do significantly better than $U^*$. These results not only refine previous results in Stackelberg games and contract design, but also lead to new results for Bayesian persuasion with a learning agent and all generalized principal-agent problems where the agent does not have private information.
Apr 24, 2025
Information Design with Unknown Prior
Jan 5, 2025
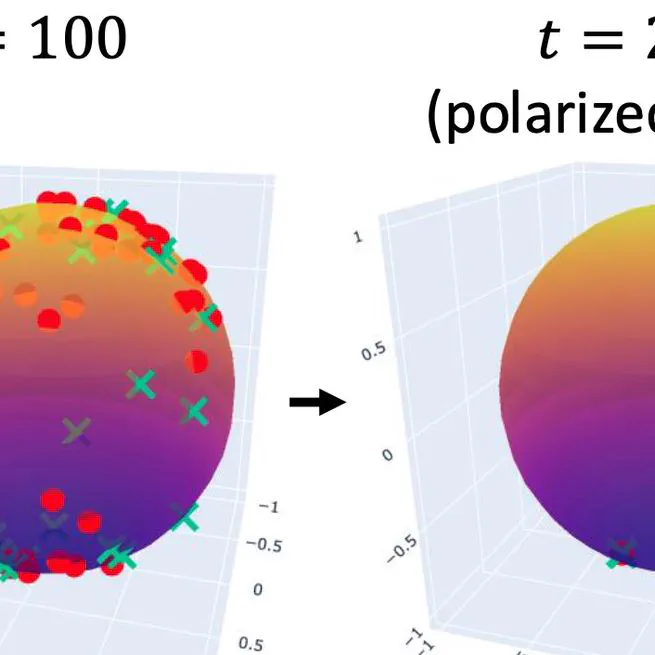
User-Creator Feature Polarization in Recommender Systems with Dual Influence
Recommender systems serve the dual purpose of presenting relevant content to users and helping content creators reach their target audience. The dual nature of these systems naturally influences both users and creators: users’ preferences are affected by the items they are recommended, while creators may be incentivized to alter their content to attract more users. We define a model, called user-creator feature dynamics, to capture the dual influence of recommender systems. We prove that a recommender system with dual influence is guaranteed to polarize, causing diversity loss in the system. We then investigate, both theoretically and empirically, approaches for mitigating polarization and promoting diversity in recommender systems. Unexpectedly, we find that common diversity-promoting approaches do not work in the presence of dual influence, while relevancy-optimizing methods like top-$k$ truncation can prevent polarization and improve diversity of the system.
Dec 10, 2024
Bias Detection via Signaling
Dec 1, 2024
Multi-Sender Persuasion: A Computational Perspective
Jul 1, 2024
Learning Thresholds with Latent Values and Censored Feedback
May 1, 2024
Sample Complexity of Forecast Aggregation
Dec 1, 2023
From Monopoly to Competition: Optimal Contests Prevail
Feb 1, 2023
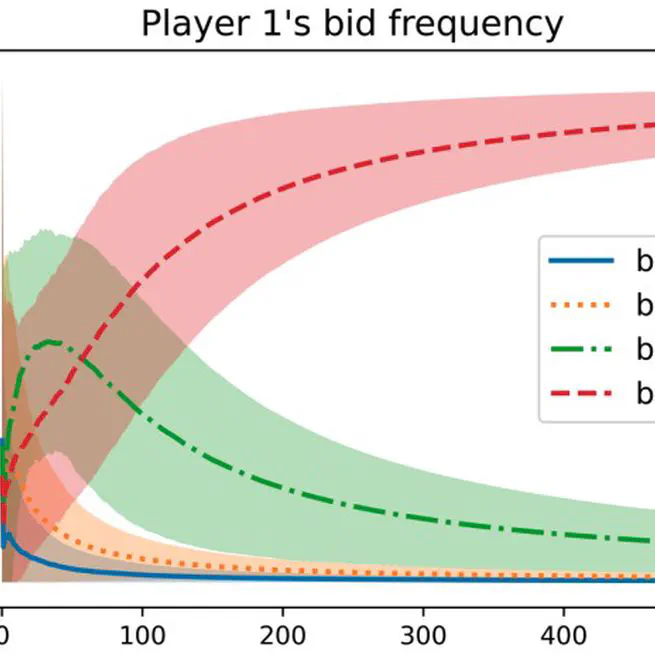
Nash Convergence of Mean-Based Learning Algorithms in First Price Auctions
The convergence properties of learning dynamics in repeated auctions is a timely and important question, with numerous applications in, e.g., online advertising markets. This work focuses on repeated first-price auctions where bidders with fixed values learn to bid using mean-based algorithms — a large class of online learning algorithms that include popular no-regret algorithms such as Multiplicative Weights Update and Follow the Perturbed Leader. We completely characterize the learning dynamics of mean-based algorithms, under two notions of convergence: (1) time-average: the fraction of rounds where bidders play a Nash equilibrium converges to 1; (2) last-iterate: the mixed strategy profile of bidders converges to a Nash equilibrium. Specifically, the results depend on the number of bidders with the highest value:
Apr 25, 2022